

Dirbtiniu intelektu paremtas turinys šiandien naudojamas beveik visur. Tačiau ar jis iš tiesų naudingas SEO rezultatams? Apžvelkime, kaip veikia DI generuojamas turinys, kokius privalumus bei trūkumus jis turi ir kaip jį taikyti taip, kad nenukentėtų svetainės pozicijos paieškos sistemose.
Automatizuotas turinio kūrimas jau tapo kasdienybe ir panašu, kad ši tendencija tik stiprės. Europol atliktas tyrimas rodo, kad jau kitais metais net iki 90 % internete esančio turinio gali būti vienaip ar kitaip susiję su dirbtiniu intelektu.
Svarbu suprasti, kad DI kuriamas turinys neapsiriboja vien tekstais. Tai gali būti trumpi mygtukų aprašymai interneto svetainėje, aiškinamieji vaizdo įrašai ar net ilgi straipsniai su iliustracijomis.
Tinkamai naudojamas ir suderintas su prekės ženklo strategija bei verslo tikslais, dirbtinis intelektas gali padėti sparčiau kurti turinį, pagerinti matomumą paieškoje bei padidinti lankytojų ir konversijų skaičių. Tačiau netinkamas jo naudojimas gali neigiamai paveikti tiek SEO rezultatus, tiek pačio prekės ženklo reputaciją.
Toliau aptarsime, kaip reikėtų naudoti DI generuojamą turinį ir atsakysime į svarbiausius klausimus:
- Kaip veikia DI kuriamas turinys?
- Ar toks turinys yra etiškas ir tvarus?
- Kokia yra „Google“ pozicija?
- Ar DI turinys gali pagerinti SEO rezultatus, ar juos pabloginti?
- Kuriose srityse jis naudojamas dažniausiai?
- Kaip efektyviai taikyti dirbtinį intelektą turinio kūrime?
Kas yra DI sugeneruotas turinys?
DI generuojamu turiniu vadinami tekstai, vaizdai, garsas ar vaizdo medžiaga, kuriuos sukuria ne žmogus, o kompiuterinės sistemos. Tokį turinį kuria mašininio mokymosi modeliai, gebantys tam tikru lygiu atkartoti žmogaus kūrybinius procesus: rašymą, piešimą, kalbėjimą, muzikos kūrimą, fotografavimą ar net judesių atkūrimą filmuotoje medžiagoje.

Šiandien egzistuoja daugybė įrankių, galinčių generuoti skirtingo tipo turinį.
Pavyzdžiui:
- „ChatGPT“ yra universalus generatyvinio DI sprendimas, tinkantis tinklaraščių tekstams, tyrimams ar programinio kodo kūrimui. Panašiu principu veikia ir „Claude“, „Google Gemini“, „Microsoft Copilot“ bei „Perplexity“.
- „Jasper AI“ orientuojasi į rinkodaros užduotis ir gali padėti rengiant socialinių tinklų įrašus ar reklaminį tekstą.
- „MidJourney“ bei „DALL-E“ leidžia pagal tekstines užklausas generuoti vaizdus, tinkamus straipsniams, el. laiškams ar socialinių tinklų kampanijoms.
- „Lumen5“ suteikia galimybę kurti įvairaus pobūdžio reklaminius vaizdo įrašus prekės ženklams.
Generavimas, automatizavimas ir pagalba kuriant turinį
Dirbtinį intelektą galima naudoti ne tik tiesioginiam turinio kūrimui. Jis taip pat pasitelkiamas idėjų generavimui, informacijos paieškai, faktų tikrinimui ar tekstų redagavimui.
Žmogaus įsitraukimas vis tiek išlieka svarbus, tačiau jo mastą kiekvienas pasirenka individualiai.
DI generuojamas turinys
Tokiu atveju naudotojas pateikia užklausą, o DI sistema pati sukuria tekstą ar kitą turinį, kurį vėliau galima publikuoti arba redaguoti.
DI automatizuotas turinys
Tai turinys, kuris sukuriamas beveik be žmogaus įsikišimo arba visiškai automatiškai. Pavyzdžiui, sistema gali automatiškai generuoti produktų puslapių meta pavadinimus kiekvieną kartą įkeliant naują prekę į elektroninę parduotuvę.
DI padedamas turinio kūrimas
Šiuo atveju dirbtinis intelektas padeda kūrybos procese, tačiau pats galutinio turinio nesukuria. Tai gali būti statistikos paieška argumentams pagrįsti arba detalios straipsnio struktūros parengimas.
Kaip dirbtinis intelektas kuria turinį
Norint suprasti, kaip DI platformos generuoja turinį, pirmiausia reikia išsiaiškinti, kas jos yra ir kokiu principu veikia.
Nors tema gana techninė, pats veikimo principas gana aiškus. Tokios sistemos apmokomos naudojant milžiniškus duomenų kiekius, kad gebėtų atpažinti ryšius, pasikartojančius modelius ir reikšmes. Būtent tai leidžia joms kurti naują turinį.
Mąstymo imitacija
Dirbtinis intelektas iš tiesų nemąsto, tačiau jo veikimas dažnai sukuria tokį įspūdį. Taip yra todėl, kad šios sistemos paremtos neuroniniais tinklais.
Neuroninis tinklas yra kompiuterinė sistema, sukurta pagal žmogaus smegenų veikimo principus. Žmogaus smegenyse neuronai jungiasi tarpusavyje, o šie ryšiai leidžia mums mąstyti, prisiminti informaciją ar patirti emocijas.
Panašiai veikia ir dirbtiniai neuroniniai tinklai. Juose naudojami dirbtiniai neuronai, vadinami mazgais, kurie organizuojami sluoksniais. Vienas sluoksnis gali būti atsakingas už formų atpažinimą, kitas už spalvas ar kontūrus.
Pavyzdžiui, jei neuroninis tinklas skirtas vaizdų atpažinimui, jam gali būti pateikta nuotrauka, kurioje matomas baldas su keturiomis kojomis, sėdimąja dalimi ir atlošu. Skirtingi sluoksniai identifikuoja atskirus elementus, o galutinis rezultatas leidžia sistemai nustatyti, kad tai yra kėdė.
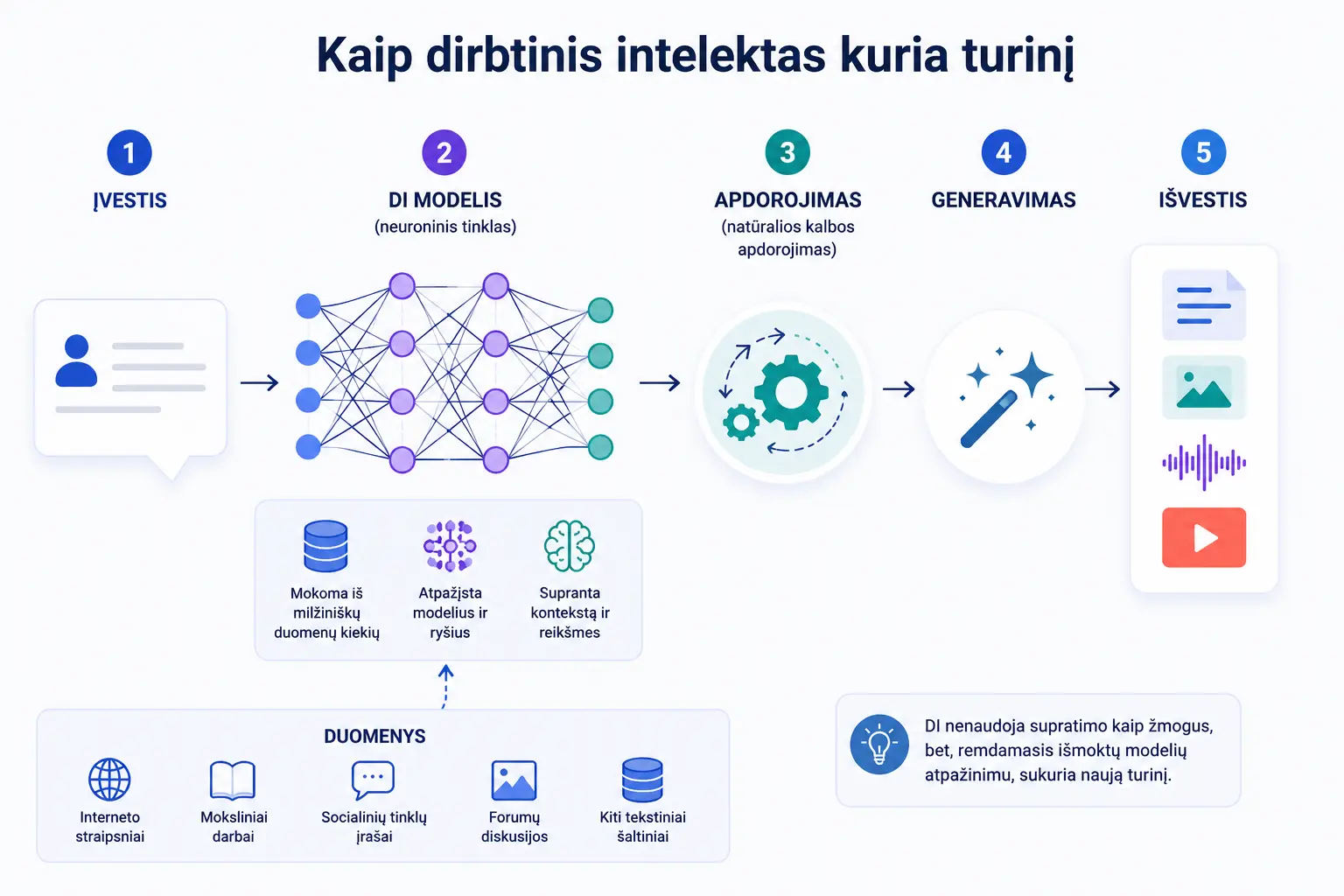
Tokios platformos kaip „ChatGPT“ remiasi specifiniu neuroninių tinklų tipu, vadinamu didžiaisiais kalbos modeliais arba LLM.
Šie modeliai sukurti tam, kad suprastų žmogaus kalbą ne tik gramatikos ar sakinių struktūros lygmenyje. Jie analizuoja ir reikšmes, kontekstą bei tarpusavio sąsajas tarp žodžių ir sakinių.
Natūralios kalbos apdorojimas
Gebėjimą suprasti žmogaus kalbą DI sistemos įgauna pasitelkdamos natūralios kalbos apdorojimo technologijas.
Tai plati dirbtinio intelekto sritis, apimanti metodus, leidžiančius kompiuteriams interpretuoti žmonių kalbą. Šiai kategorijai priskiriami vertimo įrankiai, emocijų analizė tekstuose, automatiniai vaizdo įrašų subtitrai ir panašūs sprendimai.
„Google“ natūralios kalbos apdorojimą apibūdina : „Kaip dirbtinio intelekto šaka, NLP (natūralios kalbos apdorojimas) naudoja mašininį mokymąsi tekstui ir duomenims apdoroti bei interpretuoti. Natūralios kalbos atpažinimas ir natūralios kalbos generavimas yra NLP rūšys.“
Didieji kalbos modeliai šiuos principus išplečia sujungdami:
- itin didelius neuroninius tinklus
- milžiniškus mokymui naudojamų duomenų kiekius
Mokymo medžiaga gali būti labai įvairi:
- interneto straipsniai
- moksliniai darbai
- socialinių tinklų įrašai
- forumų diskusijos
- įvairūs tekstiniai šaltiniai
Analizuodami šiuos duomenis, modeliai mokosi atpažinti kalbos dėsningumus ir palaipsniui suformuoja sudėtingą kalbos suvokimo sistemą.
Prognozavimo principu veikiantys modeliai
Kai DI sistema įgauna pakankamai platų kalbos supratimą, ji gali numatyti, kokie žodžiai ar sakiniai turėtų sekti toliau. Šis gebėjimas ir leidžia generuoti naują turinį nuo nulio.
Dauguma šiuolaikinių DI platformų turi pokalbio principu veikiančią sąsają arba API, kurioje naudotojas pateikia instrukcijas. Dažniausiai tai būna užklausa, vadinama promptu.
Rinkodaros kontekste promptą galima palyginti su užduotimi, kurią žmogus pateiktų tekstų kūrėjui.
Sistema analizuoja užklausą, interpretuoja jos tikslą ir pagal tai sugeneruoja turinį.
DI galimybės neapsiriboja tekstu
Vaizdų, garso ar vaizdo įrašų generavimo įrankiai taip pat gali naudoti natūralios kalbos apdorojimą tam, kad suprastų pateiktą užklausą. Tačiau vien to nepakanka galutiniam rezultatui sukurti, todėl naudojamos papildomos technologijos.
Tokie vaizdų generavimo įrankiai kaip „DALL-E“ ar „MidJourney“ dažnai remiasi vadinamaisiais difuzijos modeliais. Jie apmokomi palaipsniui įterpiant atsitiktinį triukšmą į vaizdus ir mokant sistemą šį procesą apsukti atgal.
Tai galima palyginti su seno televizoriaus ekrane matomu juodai baltu mirgėjimu. Pradžioje sistema mato tik chaotišką triukšmą, tačiau gavusi tekstinę užklausą pradeda jį „valyti“, kol susiformuoja aiškus vaizdas.
Šiandien egzistuoja ir įrankiai, galintys kurti:
- interneto svetainių dizainą
- logotipus
- spaudos maketus
- rinkodaros vizualus
Anksčiau tokios užduotys buvo beveik išimtinai grafikos ar interneto dizainerių sritis.
Vaizdo įrašų generavimas yra dar sudėtingesnis procesas, nes reikia sukurti nuoseklią kadrų seką, kuri judėtų logiškai ir vientisai.
Iš esmės visas DI veikimas paremtas modelių ir pasikartojimų atpažinimu. Jei sistema apmokoma pakankamu kiekiu tinkamos medžiagos, ji gali generuoti beveik bet kokio tipo turinį.
Garso generavimo atveju modeliai mokomi naudojant:
- muziką
- kalbą
- aplinkos garsus
- įvairius garso efektus
Sistema mokosi atpažinti ritmus, instrumentus, balsus, tonacijas bei kitus garsinius elementus. Kaip ir kalbos modeliai, ji geba prognozuoti, kas turėtų sekti toliau.
Didžiųjų kalbos modelių tikslumas ir šališkumas
Dirbtinio intelekto veikime labai tinka principas „kokie duomenys įvedami, tokį rezultatą ir gausi“. Kadangi modeliai mokomi naudojant konkrečius duomenų rinkinius, jie perima ne tik jų stipriąsias savybes, bet ir trūkumus.
Nors generatyvinis DI nėra tobulas, jo tikslumas šiandien gana aukštas.
Tam vertinti naudojami specialūs testai, kuriuose pateikiami įvairaus sudėtingumo klausimai: nuo bendrinių žinių iki ekspertinio lygio užduočių skirtingose srityse. Populiariausi generatyvinio DI modeliai tokiuose testuose dažniausiai pasiekia apie 85-88 % tikslumą.
Tačiau kartu modeliai gali paveldėti ir mokymo duomenyse esančius šališkumus.
LLM tyrimai rodo, kad kai kurie modeliai humanitarines disciplinas dažniau sieja su moterimis, o tiksliuosius mokslus su vyrais. Taip pat pastebimi šališkumai, susiję su:
- rase
- religija
- amžiumi
- negalia
Dar viena problema yra vadinamosios haliucinacijos. Jei sistema neturi pakankamai informacijos konkrečia tema, ji gali pradėti kurti neegzistuojančius faktus ar klaidingą informaciją. Taip nutinka ir todėl, kad modeliai dažnai sukurti taip, jog stengtųsi pateikti atsakymą bet kokia kaina.
Ką svarbu prisiminti?
DI sugeneruotą turinį visada verta vertinti kritiškai. Net ir kokybiškas modelis gali pateikti netikslumų, todėl prieš publikuojant informaciją rekomenduojama, kad ją peržiūrėtų žmogus.
DI generuojamas turinys ir SEO
Daugeliui gali būti netikėta, tačiau „Google“ savaime neprieštarauja dirbtinio intelekto kuriamam turiniui. Paieškos sistemai svarbiausia ne tai, kas sukūrė tekstą, o jo kokybė ir nauda naudotojui.
„Google“ požiūris į DI turinį
„ChatGPT“, išpopuliarinęs generatyvinį dirbtinį intelektą plačiajai auditorijai, buvo pristatytas 2022 metų pabaigoje. Netrukus po to, 2023 metų vasarį, „Google“ savo „Search Central“ tinklaraštyje paskelbė oficialią poziciją apie DI kuriamą turinį.
„Google“ paieškos algoritmai siekia iškelti originalų ir aukštos kokybės turinį.
Didžiausias dėmesys skiriamas ne tam, kokiu būdu turinys buvo sukurtas, o jo kokybei. Būtent toks požiūris daugelį metų leido pateikti naudotojams patikimus ir vertingus paieškos rezultatus.
Maždaug prieš dešimtmetį buvo kilęs susirūpinimas dėl masiškai kuriamo, tačiau žmonių rašyto, nekokybiško turinio. Vis dėlto „Google“ nepasirinko drausti viso žmogaus sukurto turinio. Vietoje to buvo tobulinami algoritmai, kad jie geriau atpažintų ir aukščiau reitinguotų kokybišką informaciją.
Iš esmės tai reiškia, kad DI sukurtas turinys gali būti vertinamas palankiai, jei jis yra kokybiškas ir naudingas naudotojams. Tačiau pastaruoju metu akcentai šiek tiek pasikeitė. Dabar daugiau dėmesio skiriama ne vien kokybei, bet ir kovai su šlamštiniu turiniu.
2025 metų kovą atnaujintoje „Search Central“ dokumentacijoje pateikiama tokia pozicija:
Naudojant generatyvinio DI įrankius didelio kiekio puslapių kūrimui be realios vertės naudotojams, gali būti pažeidžiama „Google“ šlamšto politika, susijusi su masiniu turinio generavimu.
Tame pačiame dokumente aiškiai minima, kad dirbtinis intelektas gali būti naudingas tyrimams ar struktūros kūrimui, tačiau pernelyg didelis pasikliovimas DI tekstų rašymui gali būti vertinamas neigiamai.
Šį požiūrį sustiprina ir tai, kad „Google“ neseniai savo rankinio vertinimo komandai nurodė DI sukurtą turinį dažniau vertinti kaip žemos kokybės.
Ką tai reiškia praktikoje?
Svarbiausia orientuotis į kokybę, o ne į kiekį. Dirbtinį intelektą verta naudoti planavimui, informacijos paieškai ar struktūros kūrimui, tačiau galutinį tekstą turėtų peržiūrėti žmogus. Net jei DI sugeneruoja straipsnį, jis turi būti redaguotas taip, kad skambėtų natūraliai ir autentiškai.
Kaip nekokybiškas DI turinys gali pakenkti SEO rezultatams
„Google“ algoritmai sukurti tam, kad naudotojams pateiktų kuo vertingesnius rezultatus. Jei paieškoje dominuotų prastos kokybės svetainės, naudotojai greičiausiai rinktųsi kitą paieškos sistemą.
Dėl šios priežasties turinys, kurį algoritmai vertina kaip menkavertį, dažniausiai praranda pozicijas paieškos rezultatuose.
„Google“ politika dėl masinio turinio generavimo aiškiai pabrėžia problemą, kai DI naudojamas didelio kiekio puslapių kūrimui nesukuriant papildomos vertės naudotojui.
Vienas iš pavyzdžių yra „SE Ranking“ atliktas eksperimentas. Buvo sukurta 20 naujų interneto svetainių, kurių visas turinys sugeneruotas dirbtinio intelekto. Iš pradžių rezultatai atrodė sėkmingi, tačiau 2025 metų vasarį visos anksčiau pasiektos raktažodžių pozicijos staiga dingo.
Tiksli priežastis nėra žinoma. Tai galėjo būti:
- rankinis svetainių vertinimas
- „Google“ algoritmo atnaujinimas
- patobulintas šlamšto aptikimas
Tačiau akivaizdu viena: trumpalaikė nauda, pasiekta apeinant taisykles, nėra ilgalaikė strategija.
Kodėl DI turinys dažnai nėra unikalus
Dirbtinis intelektas mokosi iš jau egzistuojančio turinio, todėl jo generuojami tekstai retai būna visiškai originalūs.
Šią problemą galima sumažinti kuriant išsamias ir specifines užklausas, kuriose pateikiamos unikalios įžvalgos bei aiški kryptis nuo pat pradžių.
Tačiau jei paprasčiausiai paprašysite „ChatGPT“ pateikti straipsnių idėjų ir tada sugeneruoti vieną iš jų, rezultatas greičiausiai bus panašus į daugybę jau internete esančių tekstų. Taip veikia DI modeliai.
O jei turinys nesuteikia naujos vertės arba neišsiskiria iš konkurentų, jo galimybės užimti aukštas pozicijas paieškoje tampa labai ribotos.
Kaip DI turinys gali pagerinti SEO rezultatus
Kai pagrindinis tikslas yra kokybė, generatyvinis dirbtinis intelektas gali tapti labai naudingu pagalbininku. Jis leidžia greičiau sukurti daugiau vertingo turinio.
Didesnis kokybiško turinio kiekis suteikia galimybę reitinguotis pagal platesnį raktažodžių spektrą ir pritraukti daugiau lankytojų iš organinės paieškos.
Be to, DI galima naudoti ne tik naujam turiniui kurti, bet ir jau esamų puslapių optimizavimui.
Svarbiausias aspektas išlieka tas pats: turinys turi suteikti realią vertę naudotojui. Būtent toks turinys turi daugiausia galimybių pasiekti aukštas pozicijas paieškoje ir pritraukti naujus lankytojus.
Pavyzdžiui, dirbtinį intelektą galima naudoti:
- detalių straipsnių struktūrų kūrimui
- SEO idėjų generavimui
- informacijos paieškai
- faktų tikrinimui
- esamų puslapių tobulinimui
- optimizavimo rekomendacijoms
SEO tobulinimo pasiūlymų gavimas gali būti labai paprastas procesas. Kartais pakanka įkelti esamą tekstą į „ChatGPT“ ir paprašyti rekomendacijų.
Taip pat egzistuoja specializuoti įrankiai, sukurti būtent SEO optimizavimui, pavyzdžiui, „Semrush Content Toolkit“.
Toliau aptarsime daugiau praktinių būdų, kaip efektyviai naudoti DI generuojamą turinį SEO strategijoje.
„Google“ paieškos algoritmai siekia iškelti originalų ir aukštos kokybės turinį.
Didžiausias dėmesys skiriamas ne tam, kokiu būdu turinys buvo sukurtas, o jo kokybei. Būtent toks požiūris daugelį metų leido pateikti naudotojams patikimus ir vertingus paieškos rezultatus.
Maždaug prieš dešimtmetį buvo kilęs susirūpinimas dėl masiškai kuriamo, tačiau žmonių rašyto, nekokybiško turinio. Vis dėlto „Google“ nepasirinko drausti viso žmogaus sukurto turinio. Vietoje to buvo tobulinami algoritmai, kad jie geriau atpažintų ir aukščiau reitinguotų kokybišką informaciją.
Iš esmės tai reiškia, kad DI sukurtas turinys gali būti vertinamas palankiai, jei jis yra kokybiškas ir naudingas naudotojams. Tačiau pastaruoju metu akcentai šiek tiek pasikeitė. Dabar daugiau dėmesio skiriama ne vien kokybei, bet ir kovai su šlamštiniu turiniu.
2025 metų kovą atnaujintoje „Search Central“ dokumentacijoje pateikiama tokia pozicija:
Naudojant generatyvinio DI įrankius didelio kiekio puslapių kūrimui be realios vertės naudotojams, gali būti pažeidžiama „Google“ šlamšto politika, susijusi su masiniu turinio generavimu.
Tame pačiame dokumente aiškiai minima, kad dirbtinis intelektas gali būti naudingas tyrimams ar struktūros kūrimui, tačiau pernelyg didelis pasikliovimas DI tekstų rašymui gali būti vertinamas neigiamai.
Šį požiūrį sustiprina ir tai, kad „Google“ neseniai savo rankinio vertinimo komandai nurodė DI sukurtą turinį dažniau vertinti kaip žemos kokybės.
Ką tai reiškia praktikoje?
Svarbiausia orientuotis į kokybę, o ne į kiekį. Dirbtinį intelektą verta naudoti planavimui, informacijos paieškai ar struktūros kūrimui, tačiau galutinį tekstą turėtų peržiūrėti žmogus. Net jei DI sugeneruoja straipsnį, jis turi būti redaguotas taip, kad skambėtų natūraliai ir autentiškai.
Kaip nekokybiškas DI turinys gali pakenkti SEO rezultatams
„Google“ algoritmai sukurti tam, kad naudotojams pateiktų kuo vertingesnius rezultatus. Jei paieškoje dominuotų prastos kokybės svetainės, naudotojai greičiausiai rinktųsi kitą paieškos sistemą.
Dėl šios priežasties turinys, kurį algoritmai vertina kaip menkavertį, dažniausiai praranda pozicijas paieškos rezultatuose.
„Google“ politika dėl masinio turinio generavimo aiškiai pabrėžia problemą, kai DI naudojamas didelio kiekio puslapių kūrimui nesukuriant papildomos vertės naudotojui.
Vienas iš pavyzdžių yra „SE Ranking“ atliktas eksperimentas. Buvo sukurta 20 naujų interneto svetainių, kurių visas turinys sugeneruotas dirbtinio intelekto. Iš pradžių rezultatai atrodė sėkmingi, tačiau 2025 metų vasarį visos anksčiau pasiektos raktažodžių pozicijos staiga dingo.
Tiksli priežastis nėra žinoma. Tai galėjo būti:
- rankinis svetainių vertinimas
- „Google“ algoritmo atnaujinimas
- patobulintas šlamšto aptikimas
Tačiau akivaizdu viena: trumpalaikė nauda, pasiekta apeinant taisykles, nėra ilgalaikė strategija.
Kodėl DI turinys dažnai nėra unikalus
Dirbtinis intelektas mokosi iš jau egzistuojančio turinio, todėl jo generuojami tekstai retai būna visiškai originalūs.
Šią problemą galima sumažinti kuriant išsamias ir specifines užklausas, kuriose pateikiamos unikalios įžvalgos bei aiški kryptis nuo pat pradžių.
Tačiau jei paprasčiausiai paprašysite „ChatGPT“ pateikti straipsnių idėjų ir tada sugeneruoti vieną iš jų, rezultatas greičiausiai bus panašus į daugybę jau internete esančių tekstų. Taip veikia DI modeliai.
O jei turinys nesuteikia naujos vertės arba neišsiskiria iš konkurentų, jo galimybės užimti aukštas pozicijas paieškoje tampa labai ribotos.
Kaip DI turinys gali pagerinti SEO rezultatus
Kai pagrindinis tikslas yra kokybė, generatyvinis dirbtinis intelektas gali tapti labai naudingu pagalbininku. Jis leidžia greičiau sukurti daugiau vertingo turinio.
Didesnis kokybiško turinio kiekis suteikia galimybę reitinguotis pagal platesnį raktažodžių spektrą ir pritraukti daugiau lankytojų iš organinės paieškos.
Be to, DI galima naudoti ne tik naujam turiniui kurti, bet ir jau esamų puslapių optimizavimui.
Svarbiausias aspektas išlieka tas pats: turinys turi suteikti realią vertę naudotojui. Būtent toks turinys turi daugiausia galimybių pasiekti aukštas pozicijas paieškoje ir pritraukti naujus lankytojus.
Pavyzdžiui, dirbtinį intelektą galima naudoti:
- detalių straipsnių struktūrų kūrimui
- SEO idėjų generavimui
- informacijos paieškai
- faktų tikrinimui
- esamų puslapių tobulinimui
- optimizavimo rekomendacijoms
SEO tobulinimo pasiūlymų gavimas gali būti labai paprastas procesas. Kartais pakanka įkelti esamą tekstą į „ChatGPT“ ir paprašyti rekomendacijų.
Taip pat egzistuoja specializuoti įrankiai, sukurti būtent SEO optimizavimui, pavyzdžiui, „Semrush Content Toolkit“.
DI turinys ir „AI Overviews“
Gali atrodyti logiška manyti, kad „AI Overviews“ funkcija, kai „Google“ paieškos viršuje pateikiamos DI sugeneruotos santraukos, daugiausia remiasi žmonių sukurtu turiniu.
Tačiau neseniai atliktas tyrimas parodė, kad apie 91,4 % turinio, cituojamo „AI Overviews“ atsakymuose, bent iš dalies buvo sugeneruota dirbtinio intelekto. Daugeliu atvejų prie jo kūrimo prisidėjo ir žmogus.
Svarbu paminėti, kad šiame tyrime naudotos DI atpažinimo sistemos, kurių tikslumas nėra absoliutus. Kai kurie tyrimai rodo, kad geriausi DI aptikimo įrankiai gali pasiekti iki 99 % tikslumą, tačiau skirtingų sistemų rezultatai smarkiai skiriasi.
Jeigu tyrimo išvados yra tikslios, tai gali reikšti, kad kokybiško DI turinio kūrimas didina tikimybę patekti į „AI Overviews“ atsakymus ir taip pagerinti svetainės matomumą paieškoje.
Etika ir tvarumas
Diskusijos apie generatyvinio dirbtinio intelekto etiką bei tvarumą vyksta itin aktyviai. Vienas svarbiausių klausimų šiandien yra ne tik tai, ką DI gali padaryti, bet ir ar visa tai apskritai turėtų būti daroma.
Intelektinė nuosavybė
Didžioji dalis etinių diskusijų susijusi su duomenimis, kurie naudojami didžiųjų kalbos modelių ir kitų DI sistemų apmokymui.
Nors didelė dalis šios informacijos yra viešai prieinama internete, jos autorinės teisės vis tiek priklauso kūrėjams. Dėl šios priežasties nemažai žmonių mano, kad turinio naudojimas DI mokymui be leidimo gali pažeisti autorių teises.
Ši problema ypač aktuali:
- rašytojams
- iliustratoriams
- dizaineriams
- kitiems kūrybinių profesijų atstovams
Pavyzdžiui, fantastikos iliustratoriaus Grego Rutkowskio vardas DI užklausose buvo panaudotas daugiau nei 400 tūkstančių kartų. Internete taip pat atsirado daugybė darbų, pažymėtų jo vardu, nors pats autorius jų nekūrė.
Natūralu, kad kūrėjai nenori, jog jų darbai būtų kopijuojami be sutikimo. Taip pat kyla baimė, kad ateityje dalį kūrybinių profesijų gali pakeisti automatizuotos sistemos.

Įkvėpimas ar plagijavimas?
Kita pusė teigia, kad menas visais laikais buvo grindžiamas įkvėpimu iš kitų kūrėjų darbų. Menininkai mokosi vieni iš kitų, o kopijavimas dažnai tampa stiliaus formavimo dalimi.
Viena didžiausių problemų šiuo metu yra aiškaus reguliavimo trūkumas DI industrijoje. Tikėtina, kad ateityje atsiras daugiau taisyklių ir aiškesnių teisinių ribų, tačiau dabar kiekvienas naudotojas pats sprendžia, kiek toks naudojimas jam atrodo priimtinas.
Patarimas – Jeigu kyla abejonių dėl intelektinės nuosavybės, verta rinktis DI įrankius, kurie pateikia informacijos šaltinius. Tokios platformos kaip „Perplexity“ ar „Gemini“ leidžia matyti, iš kur paimta informacija, todėl šiuos šaltinius galima įtraukti ir į savo turinį.
Tvarumas
Kalbant apie tvarumą, daugelis tyrimų, tarp jų ir MIT analizė, atkreipia dėmesį į dideles dirbtinio intelekto industrijos elektros, vandens bei kitų išteklių sąnaudas. Vis dėlto Oksfordo universiteto publikacijoje pažymima, kad skirtingų platformų resursų naudojimas labai skiriasi, o didelė dalis statistikos paremta tik apytikriais vertinimais. Dėl to sudėtinga tiksliai įvertinti, kokį poveikį aplinkai turi vieno žmogaus naudojimasis DI įrankiais.
Straipsnio pabaigoje Oksfordo universiteto profesorius Charlie Wilsonas pateikia gana racionalų požiūrį į šią temą.
Dirbtinį intelektą verta naudoti atsakingai, kaip ir bet kurią daug energijos naudojančią technologiją. Tačiau jei pagrindinis rūpestis yra anglies pėdsakas, kur kas didesnę įtaką aplinkai dažniausiai turi kelionės, mityba bei namų energijos vartojimas.
Ar DI naudojimas tinka jūsų prekės ženklui?
Kiekvienas verslas turi pats nuspręsti, ar dirbtinis intelektas dera su jo komunikacija, auditorija ir vertybėmis.
Pavyzdžiui, aplinkosaugos srityje veikianti organizacija gali sulaukti neigiamos auditorijos reakcijos aktyviai naudodama DI sprendimus. Tuo tarpu technologijų sektoriaus įmonės dažnai siekia parodyti inovatyvumą ir naujų technologijų integraciją, todėl DI joms gali tapti natūralia strategijos dalimi.
Kaip atsakingai naudoti DI generuojamą turinį
Teorinę dalį jau aptarėme, todėl metas pereiti prie praktinių rekomendacijų.
Toliau pateikiami patarimai remiasi fiktyviu kačių kavinių tinklu „Purrcolator Café“.
DI naudojimą sieskite su verslo tikslais, o ne turinio kiekiu
DI leidžia turinį kurti greitai ir palyginti paprastai. Tačiau jei tas turinys neprisideda prie verslo tikslų įgyvendinimo, jo kūrimas tampa bereikalingu laiko ir resursų švaistymu.
Pavyzdžiui, jei „Purrcolator Café“ pradėtų masiškai publikuoti straipsnius apie kačių priežiūrą, tai galėtų pritraukti skaitytojų dėmesį ir įsitraukimą, tačiau nebūtinai padidintų kavos pardavimus. Priežastis paprasta: žmonės, jau turintys kačių namuose, nebūtinai ieško vietos, kur galėtų bendrauti su kitomis katėmis.
Todėl svarbu galvoti ne apie turinio kiekį, o apie jo paskirtį.
| Tikslas | Turinio tipas | Pavyzdys |
|---|---|---|
| Potencialių klientų pritraukimas | Nukreipimo puslapiai | „Rezervuokite apsilankymą“ |
| Didesnis matomumas paieškoje | Informaciniai straipsniai | „Kaip katės padeda mažinti stresą“ |
| Prekės ženklo autoriteto stiprinimas | Ekspertinis turinys | „Kaip sukūrėme katėms draugišką verslą ir kaip tai galite padaryti jūs“ |
SEO tikslus įtraukite į užklausas DI sistemai
Viena dažniausių klaidų yra pernelyg paprastos užklausos, pavyzdžiui: „Parašyk straipsnį apie 10 populiariausių kačių veislių.“
Tokio tipo užklausa suteikia labai mažai kontrolės SEO rezultatams, nes sistemai nenurodoma, į ką ji turėtų atkreipti dėmesį: raktažodžius, struktūrą ar paieškos ketinimą.
Svarbu suprasti vieną taisyklę: jei DI sistemai aiškiai nenurodysite konkretaus veiksmo, ji jo greičiausiai neatliks.
Todėl SEO aspektai turi būti integruoti tiesiai į užklausą.
- Raktažodžiai – pirmiausia atlikite raktažodžių analizę ir aiškiai nurodykite, kokias frazes reikia naudoti tekste. Tai padidina tikimybę pritraukti organinį srautą iš paieškos sistemų.
- Paieškos ketinimas – svarbu ne tik raktažodžiai, bet ir naudotojo tikslas. Reikia aiškiai apibrėžti, kuo turinys bus aktualus auditorijai ir kaip jis turi patenkinti naudotojo poreikį.
- Struktūra – naudinga pateikti straipsnio struktūrą: H2 antraštes, H3 poskyrius, DUK sekcijas ,sąrašus Taip pat verta nurodyti, ar kuriamas tinklaraščio įrašas, informacinis puslapis ar kitas formatas.
- Esybės – SEO kontekste esybės yra konkretūs objektai: žmonės, vietovės, produktai, organizacijos, įvykiai, sąvokos Paieškos sistemos analizuoja šių objektų tarpusavio ryšius, todėl verta iš anksto suplanuoti, kokias esybes įtraukti į tekstą.
- Vidinės nuorodos – dirbtiniam intelektui galima nurodyti, į kuriuos svetainės puslapius turi būti nukreipiamos vidinės nuorodos bei kokį inkaro tekstą naudoti. Tai padeda „Google“ geriau suprasti svetainės struktūrą ir svarbiausius puslapius.
- Išorinės nuorodos – nuorodos į patikimus išorinius šaltinius gali sustiprinti straipsnio patikimumą ir parodyti, kad turinys parengtas remiantis tyrimais bei faktais.
- Struktūrizuoti duomenys – DI gali padėti ne tik rašyti tekstus, bet ir generuoti techninį kodą. Pavyzdžiui, struktūrizuoti duomenys padeda paieškos sistemoms bei kalbos modeliams geriau suprasti puslapio turinį. Jeigu svetainėje tam nenaudojami papildiniai ar automatizacija, DI galima paprašyti sugeneruoti reikiamą kodą.
Kaip tai atrodo praktikoje?
- parašyti 250-500 žodžių straipsnį apie Jūsų temą.
- įtraukti konkrečius raktažodžius
- išlaikyti lengvą ir draugišką toną
- pateikti nuorodą į straipsnį apie populiariausias kačių veisles
- naudoti H2 antraštes apie išvaizdą, charakterį ir mėgstamus dalykus
- remtis pateikta informacija apie katiną
Nebūtina publikuoti pirmosios versijos
Pirmasis DI sugeneruotas variantas neturi būti galutinis.
Pavyzdžiui, straipsnis apie Jūsų temą gali neatitikti lūkesčių arba būti per daug orientuotas į pardavimus. Jei taip nutinka, užklausą galima koreguoti, pradėti generavimą iš naujo arba paprašyti pakeisti konkrečias teksto vietas.
Galima:
- pakoreguoti toną
- sumažinti reklaminių frazių kiekį
- perrašyti tam tikrus sakinius
- išbandyti kitą DI įrankį
Tarkime, tekste pernelyg dažnai kartojami raginimai apsilankyti kavinėje ar išgerti kavos. Tokiu atveju galima aiškiai nurodyti, kad tekstas neturi būti pardaviminio pobūdžio arba pažymėti konkrečias vietas, kurias reikia perrašyti natūraliau.
Dėmesys E-E-A-T principui
Šiuolaikiniame SEO itin svarbią vietą užima tai, ką „Google“ vadina E-E-A-T principu.
Paieškos sistemos siekia iškelti originalų, kokybišką turinį, kuris demonstruoja kompetenciją, patirtį, autoritetą ir patikimumą.
Žmonės dažniausiai nesikreipia į kirpėją dėl medicininių patarimų, kaip ir nesitiki iš gydytojo profesionalios šukuosenos konsultacijos. Ieškodami informacijos dažniau pasitikime specialistais, turinčiais realios patirties konkrečioje srityje. Būtent tai ir apibūdina E-E-A-T principas.
Panašiai veikia ir „Google“ algoritmai. Didesnė tikimybė, kad aukštesnes pozicijas užims turinys, kurį sukūrė kompetentingi ir patikimi autoriai, o ne atsitiktiniai nuomonės reiškėjai.
Nors pats DI modelis negali būti laikomas tikru specialistu, jis mokomas naudojant ekspertų sukurtą turinį. Todėl kokybiškame straipsnyje svarbu pateikti:
- statistiką
- ekspertų įžvalgas
- faktinius duomenis
- autoritetingų šaltinių informaciją
Dar geriau, jei ši informacija aiškiai susieta su konkrečiais šaltiniais ar specialistais.
Tokius reikalavimus galima numatyti dar užklausoje DI sistemai arba papildyti tekstą rankiniu būdu po generavimo.
Toks metodas gali padėti:
- sustiprinti pasitikėjimą tarp skaitytojų
- pagerinti matomumą „Google“ paieškoje
- didinti turinio autoritetą
Naudokite DI kaip duomenų analizės įrankį, o ne tik tekstų kūrėją
Dirbtinis intelektas gali sugeneruoti visą tekstą nuo pradžios iki pabaigos, tačiau tai nebūtinai yra geriausias sprendimas.
Generatyvinis DI puikiai tinka straipsniams, tinklaraščio įrašams ar socialinių tinklų tekstams kurti. Tačiau jo galimybės daug platesnės. Viena stipriausių sričių yra pagalba planuojant pačią turinio strategiją.
Būtent čia DI gali suteikti daugiausia vertės.
Užklausų grupės
Dirbant su užklausų grupėmis analizuojamas ne vienas raktažodis, o tarpusavyje susijusių frazių rinkinys.
Toks požiūris leidžia puslapiui reitinguotis pagal didesnį skaičių paieškos užklausų. Be to, galima kurti tarpusavyje susijusių straipsnių tinklą aplink vieną pagrindinę temą.
Esybės ir kontekstiniai ryšiai
Esybės SEO kontekste yra konkretūs objektai ar sąvokos:
- prekės ženklai
- žmonės
- organizacijos
- produktai
- vietovės
- įvykiai
Įtraukiant jas į turinį, aktyvuojami ryšiai su „Google“ žinių baze, kurioje kaupiama informacija apie objektus ir jų sąsajas.
Tai padeda paieškos sistemoms geriau suprasti turinio kontekstą ir vertinti svetainę kaip labiau autoritetingą konkrečioje temoje.
Naudotojo ketinimo svarba
Turinio planavime svarbu atsižvelgti ne tik į raktažodžius, bet ir į tai, kokį tikslą turi skaitytojas.
Naudotojo ketinimo analizė leidžia suprasti:
- kokios informacijos žmogus ieško
- kokį klausimą jis bando išspręsti
- kokio tipo atsakymo tikisi
Tai padeda kurti turinį, kuris realiai atitinka auditorijos poreikius.
Praktinis pavyzdys
Tarkime, planuojamas straipsnis pagal raktažodį „katės ir psichologinė sveikata“.
Norint išplėsti temą, galima paprašyti DI sistemos pateikti:
- susijusių paieškos užklausų grupes
- aktualias esybes
- naudotojų ketinimo analizę
Pavyzdžiui, „Google Gemini“ gali pasiūlyti papildomas temas apie kačių naudą emocinei savijautai, stresui ar vienišumo mažinimui.
Tokiu būdu DI tampa ne tik tekstų generatoriumi, bet ir įrankiu, padedančiu kurti stipresnę SEO strategiją bei geriau suprasti auditorijos poreikius.
Naudokite mišrius darbo procesus siekdami didesnio mastelio

Vienas efektyviausių būdų suderinti turinio kokybę ir greitą gamybą yra darbo procesas, kuriame dalyvauja tiek žmogus, tiek dirbtinis intelektas.
Toks modelis leidžia greičiau kurti turinį, tačiau kartu išlaikyti aukštą kokybės standartą ir geresnius SEO rezultatus.
Turinio strategijos kūrimas kartu su DI
- Padeda analizuoti raktažodžius ir auditorijos ketinimą
- Generuoja turinio idėjas ir straipsnių temas
- Leidžia greičiau suplanuoti SEO strategiją
Pirminio straipsnio generavimas
- DI sukuria pirmąją straipsnio versiją pagal pateiktą struktūrą
- Pagreitina pasiruošimo procesą
- Leidžia daugiau dėmesio skirti kokybės gerinimui
Redagavimas ir užklausų tobulinimas
- Tikrinami faktai ir sakinių natūralumas
- Šalinami pasikartojimai ir dirbtinai skambančios vietos
- Prireikus koreguojamas promptas ir generuojama nauja versija
Automatizuotas SEO optimizavimas
- Automatiškai pridedamos vidinės nuorodos
- Generuojami struktūrizuoti duomenys
- Analizuojamas SEO potencialas ir raktažodžių panaudojimas
Galutinė žmogaus peržiūra
- Įvertinamas teksto tikslumas ir kokybė
- Tikrinamas E-E-A-T principų laikymasis
- Turinio tonas pritaikomas prie prekės ženklo komunikacijos
Publikavimas
- Straipsnis publikuojamas tik po pilnos peržiūros
- Užtikrinama geresnė ilgalaikė SEO vertė
- Išlaikomas balansas tarp greičio ir kokybės
Specializuojasi end-to-end SEO – nuo strategijos formavimo iki techninio įgyvendinimo ir svetainių migracijų. Jo patirtis apima darbą su tarptautiniais projektais Lietuvoje ir daugiau nei 20 rinkų, įskaitant tokius prekių ženklus kaip „Cedral“, „Eternit“, „Euronit“, „Siniat“, „Promat“ ir „Skamowall“.